AI Today
Innovations, Challenges, and Opportunities
AI Today
2023 was a breakout year for AI, to say the least! As the trends have shifted and we were fortunate to witness the release of multiple models, it would be helpful to summarize the most crucial trends and look at what lies ahead.
What is GenAI
Before we dive into the details further, let's define GenAI. GenAI or Generative artificial intelligence, as defined by McKinsey, refers to algorithms used to create new content - this includes audio, code, images, text, simulations, and videos.
With GenAI now publicly available, numerous professionals utilize it daily. The technology, media, and telecommunications sectors are leading in terms of the regular application of GenAI at work.
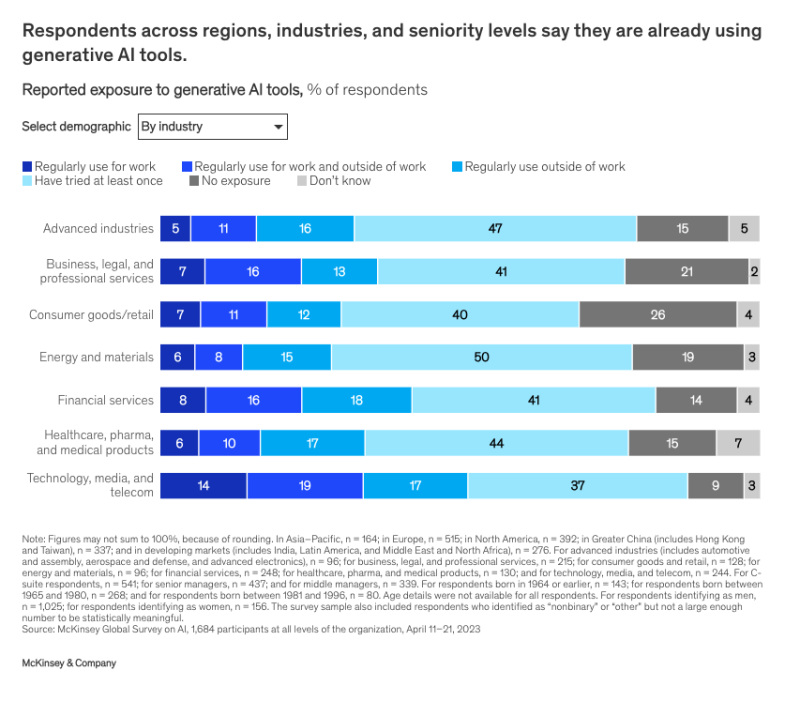
Reported exposure to Generative AI tools. Source: McKinsey & Company
An Explosion of Large Language Models (LLMs)
Following the release of ChatGPT at the end of 2023, Large Language Models have become the biggest and most advanced category in the realm of GenAI. Notably, ChatGPT, likely the most famous LLM at present, went from zero to being utilised by over 100 million people every week in barely a year.
The success of ChatGPT has shifted the common perception of AI, expanding from robots to include language models too. The timeline below shows a (small) subset of the LLMs that were released in 2023 alone. The development of LLMs is booming, further supported by the sheer amount of research papers on the topic, as more people incorporate them into everyday life.
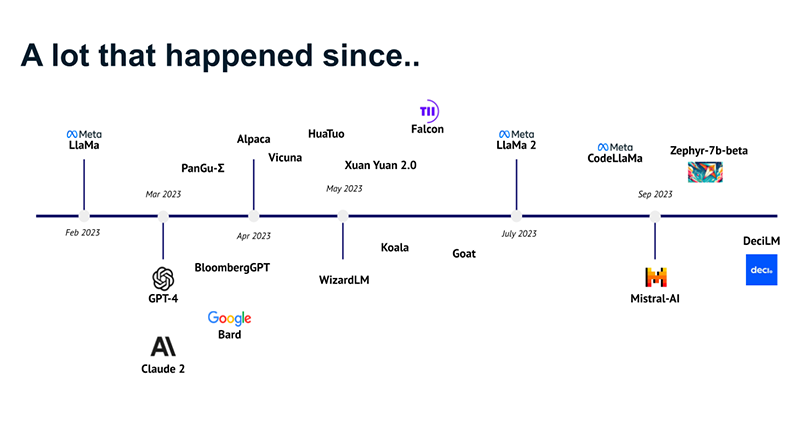
Timeline of the release of LLM models in 2023
Following additional investment and research, LLMs have experienced impressive performance gains. A striking example of this is GPT-4's performance in the Uniform Bar Exam in the United States. While GPT3.5 scored just 10%, GPT-4 got 90% of questions correct, showcasing its ability to reach (above) human-level performance on highly challenging tasks.
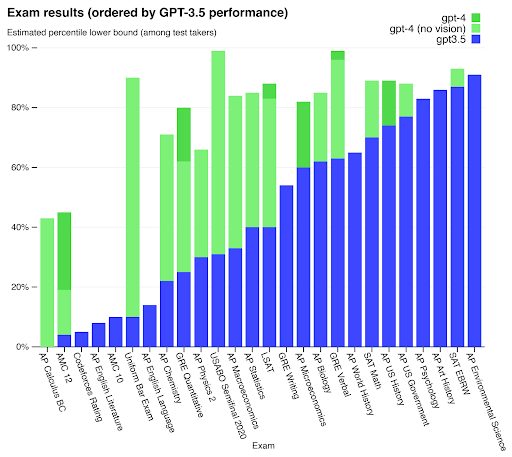
GPT results ordered by performance. Source: OpenAI
The Shift in Accessibility of LLMs
Despite these impressive results and the potential for even better performance, the future of LLMs remains uncertain, with open access becoming increasingly limited. A prime example of this shift is OpenAI. The organization, which received its very name thanks to its openness to the broad public, now hides its models behind a subscription-based API. Its partnership with Microsoft further confirms this trend towards exclusivity.
The Data Dilemma
Another concern we face is the availability of high-quality data that is used to train the models. The remarkable performance of LLMs across diverse tasks stems from their training on a substantial portion of the internet. Previously, increasing the performance of LLMs often 'simply' involved supplying them with more data and increasing the model size.
But are we slowly running out of high-quality data? The amount of training data used by LLMs is growing at a much faster rate than the rate at which humans generate high-quality data for training. This might lead to running out of high-quality language data within approximately five years. Although research suggests that using generated data on top of high-quality data improves AI models' performance, this concept remains under question.

A representation of Vision Language Models
The Emergence of Vision Language Models
With single models comprehending various modalities such as text, image, and audio, LLMs are not the only type of AI models seeing rapid growth. A bright example is the Vision Language Models (VLMs), which can process and understand text and images simultaneously to perform various advanced tasks such as Visual Question Answering (VQA), image captioning, and Text-To-Image search.
Some examples of state-of-the-art VLMs are ChatGPT and LINGO-1. These models can be used for a number of tasks, ranging from making interior designs based on blueprints to increasing AI explainability by elaborating why autonomous vehicles make certain decisions.
The success of these models is attributed to large amounts of training data that include these multiple data modalities. With the necessary prompts, one can now easily generate a dataset out of text, images, or both.
While AI models perform exceptionally well with images and text, they still lag in video processing, because of the complexity of the format. Nevertheless, we expect the video generation to become the next big trend.
January 9, 2024