Query Expansion for Topic Distillery
At Media Distillery we have been working on a solution we’ve dubbed Topic Distillery™. Using technologies like speech recognition, face recognition, and topic recognition, we can automatically create short clips based on a consumer’s favourite person, topic, or interest from TV content. With this solution, TV operators can present bite-sized content extracted from long-form video content. In this article, we discuss in-depth one of these technologies and how it contributes to our innovative Snackable Content™ solution.
For the main use-case of Topic Distillery™ we look for interesting topic clips in TV content. In this process, we decide which topics to search for and how to present them. We can also allow the user themselves to provide a user query (or “topic”). This way the task becomes more closely related to a classic information retrieval problem which we refer to as “topic search.”
While we have been investigating the topic search use-case, we have experimented with a number of technologies to improve its performance. Let’s now have a look at what we learned from our experiment with query expansion.
Query Expansion
In a nutshell, query expansion is a common technology used in information retrieval to increase the number of relevant search results (“recall”) by adding related terms to a user query. There are roughly two steps in this process: how to find new terms and how to add these new terms to the existing query.
Step 1: How to find new terms
Finding new terms can be done in a bunch of different ways. One simple way is by finding synonyms of each term in the original query. You can do this in an automated way for the English language through the readily available WordNet lexical database which has modeled these types of word relations. The benefit of this method is that the terms are guaranteed to be relevant to the input term, which depending on the method is not always guaranteed. One of the downsides is that lexical databases in languages other than English aren’t as readily available, which in our case could make it more difficult for us to scale our solution to other countries.
Another more scalable method is using word embeddings. Each word embedding represents a point in high-dimensional space where the embeddings are trained in such a way that word embeddings that are closer together represent words that are semantically related. By converting each term in the user query to a word embedding we can find semantically related terms. A common method to accomplish this is called Word2Vec. Many more methods have been developed since its original creation, but Word2Vec has remained very popular. Since it’s easy to start and scale with, this is the method we’ve mostly been focusing on.
Step 2: How to add these new terms to the existing query
Once you have the expanded terms the next part is to create the expanded query. This can be as trivial as appending the expanded terms to the original terms.
A possible side-effect of this – and query expansion in general – is that the expanded terms may cause the user query to drift too far from what the user originally intended. A simple way to mitigate this is to introduce a form of weighting on the expanded query. The weight of the expanded terms, w.r.t. finding related clips, is reduced as compared to the original terms. If and how this would work depends greatly on how the search is done.
Now we would like to demonstrate through some code examples our experiences and main findings using Word2Vec approaches for Query Expansion.
Demo
We start by setting up a Python 3.6 virtual environment.

We’ll be working with the Word2Vec models provided by the library Gensim. These are not the models we used internally, but they are adequate for this demonstration. Start by installing the library itself.

The model will automatically be downloaded and stored locally the first time you try to load the model in a script.

Now that we have a model let’s see what we get with a simple topic like “cooking”.

We get back a list of the top 10 (by default) most similar terms to the input term and an associated confidence score for each. We could directly add these terms to the query, but we may end up adding terms that are completely unrelated to the original query. We can mitigate this by filtering only terms with a high confidence.



Now what if we want to expand user queries that contain multiple words?


As expected, most Word2Vec models are trained on single words. It doesn’t recognize “clean energy” as a single term, but it surely will recognize “clean” and “energy” separately. This means we need some extra preprocessing. This step can get much more complex, but for now, we’ll keep it simple and use an existing utility from Gensim.


As we see, we can still expand the query by expanding each term separately. Lastly, we create a utility function to combine the preprocessing, thresholding, and query (re-)building.



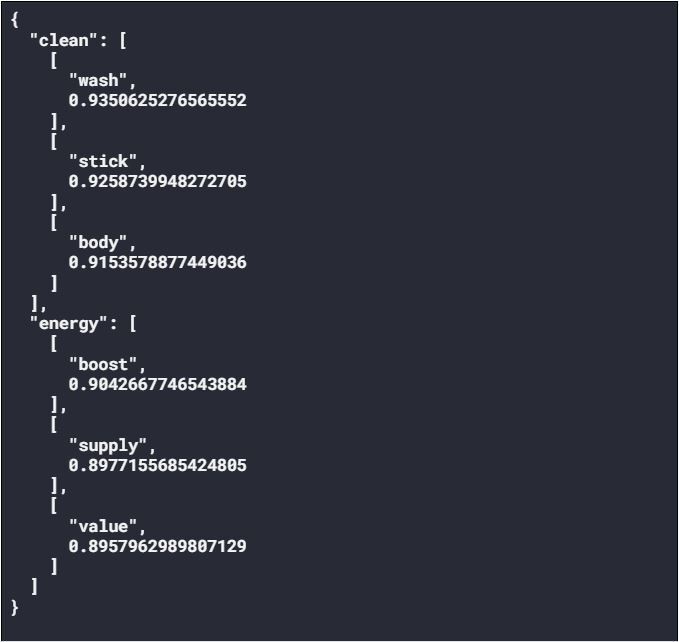
This approach appears to work well enough for the query “cooking”. The model adds useful contextual information to the query. Unfortunately for the “clean energy” example it mostly adds noise. Words like “stick” and “value” have very little to do with “clean energy”. Putting it differently, through preprocessing we have lost the meaning, or “sense”, of the query. We can address this issue using Sense2Vec.
Sense2Vec is a word embedding model that was trained to preserve the sense of its words. For example, “clean” and “energy,” separately, have different meanings than “clean energy” together. For our use-case, this means the model can work directly with multi-word phrases and preserve the sense within them. We can easily access the model without having to download it through a handy RESTful API. Using that API let’s try the same query as before. To re-use the previous “expand_query” function we’ll need a small wrapper class and an extra dependency.
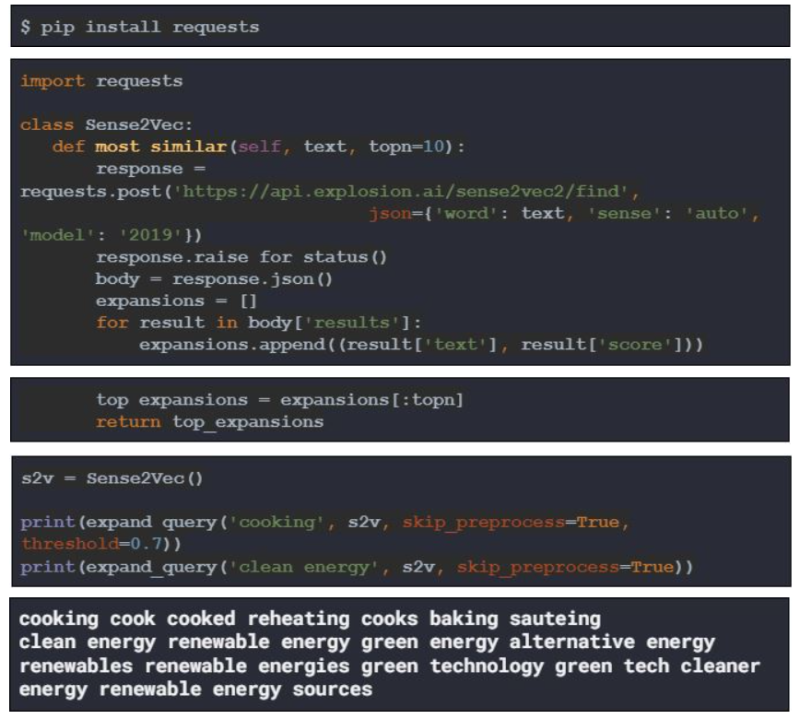
We lowered the threshold for the “cooking” query for demonstrative purposes. We see it is able to expand the query with words that are intuitively more closely related to the original query. With the “clean energy” example we see by the expanded terms it is able to preserve the original sense of the terms in the query.
Concluding Thoughts
During the experimentation on our platform, while we found the implementation of query expansion did not significantly improve our topic search use-case to find more related content, it certainly didn’t hurt our overall performance either. For some topics, query expansion introduced relevant results that we otherwise wouldn’t have found and for others, it introduced irrelevant results, resulting in a small overall improvement that we concluded wasn’t statistically significant. We only had a limited amount of annotated data available which was most likely a big factor in this result. Regardless, we gained some useful knowledge from our experimentation:
We only looked at very simple user queries. While this was already sufficient to get decent results, there are much more advanced tokenization and preprocessing steps that can be applied to deal with more complex queries.With both approaches, we needed to set some kind of threshold. Setting it too low meant potentially too many irrelevant terms were added to the query. Conversely, setting it too high meant nothing might be added to the query. We didn’t go in-depth to figure out a good setting for these thresholds, but they are still worth exploring further.You can’t expand out-of-vocabulary words. Concrete examples are “corona” or “COVID”. These terms either didn’t exist yet when the models were trained or didn’t carry the same weight they do now. This means any model we use would need to be frequently updated to keep up with current affairs.Query expansion is more focused on recall, whereas for our use-case precision is much more important. Often, not finding any results is better than finding irrelevant results.We did not explore the usefulness of lexical databases like WordNet for query expansion. (One of our issues was introducing irrelevant results.) This approach could help to mitigate that.
While the output from our experiments with query expansion for topic search wasn’t a smashing success, we did get multiple interesting findings, and there are plenty more avenues to explore. Based on these findings and experiences, we continue to be excited to explore the possibilities of query expansion in future projects. We hope you gained some useful insights, as well, about whether your use-case could benefit from this approach to query expansion, how you could quickly and easily get started, and how you could deal with some of the issues you may encounter in the process.
