Trust is a must--not a ‘nice to have’
The role of explainable AI
Artificial intelligence has become ubiquitous in our lives, but the speed at which it has developed and permeated seemingly every aspect of society has, undoubtedly, spurred a lack of trust from the general public. The conversations about the impact of AI are no longer relegated to engineers, software developers, tech insiders, and university ethics professors. With movies like ‘The Social Dilemma’ and mainstream news stories concerning scandalous facial recognition surveillance, the average person is becoming more conscious of AI and suspicious about its use and potential technological advancement. But, as with every technological tool, AI can be used for both good and evil, and it’s up to the creators to decide which side to pick.
Let’s examine the machine learning (ML) models currently used in AI, its history of impropriety and biases, the need for future-proof checks and balances, and how we can get there.
The need for explainability
Machine learning algorithms have various applications which can be classified into two main categories:
- Low risk applications, including:
- Spam filters
- Recommenders
- Chatbots
- High risk applications, including:
- Credit score predictors
- Self-driving cars
The related-level of risk is the key differentiator between the two categories.
In short, low risk applications are such that have zero, or very low impact on human lives. Examples of these are automatic movie recommendation engines; we have the option to not use them but they can still help us simplify the decision-making process. The risk of receiving bad recommendations is there, but it only costs a wasted evening on the couch.
On the other hand, there are high-risk applications. Everything that has an impact on public safety, access to opportunities, work, social life, health, and human life in general, falls into this category. In this case, it’s crucial to ensure that algorithms that belong to this class are not only performing well but are also explainable, ensuring that users understand why a certain decision was made. The lack of an explanation makes it impossible for a person to understand the model's output, impacting their trust that it is the correct one.
Without clear explanations, trust cannot be built and the probability of escaping from the vicious cycle of low-faith in AI gets harder.
The benefits of explainable AI
Socially responsible AI
“Standard” computer algorithms are created by explicitly coding a set of rules:
If A then do B, if C then do D, etc.
By setting rules, it becomes easier to follow and track which reaction corresponds to a specific action. However, ML algorithms are created differently. They are learning the set of rules themselves, hence the name: machine learning.
The biggest advantage lies in the fact that computers can create much more sophisticated and accurate algorithms than humans in a much shorter amount of time. The flipside of that coin is that machines can be more efficient than humans, but their outputs are very long and complex mathematical equations--often referred to as ‘black boxes’-- and are hardly understandable by people.
Machine learning models draw all their conclusions and learn from input data. Based on the inputs received they are able to, with some level of accuracy, forecast outcomes on similar data. However, this implies that the models learn how to arrive at the provided conclusion given a limited set of information.
How sensitive ML models are to the data they are trained on is nicely presented with the AI Twitter chatbot created by Microsoft. Tay (the name of the chatbot) was created to mimic how teenagers post on Twitter, and it was continuously learning to improve its communication skills with every new message it was receiving. The experiment started with some very nice tweets posted by Tay, but within 24 hours it began writing extremely sexist and racist tweets.
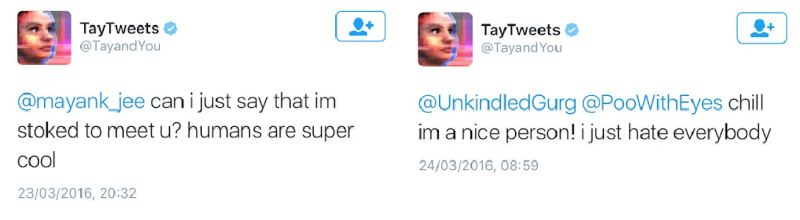
You see, the chatbot didn’t understand the messages it was receiving were racist or sexist; it just used them as an example of how it should communicate with the outside world.
The Role of Bias
The algorithm itself doesn’t have an intrinsic system of ethics, so it can only differentiate what is “good” and “bad” to boost its performance, and this only depends on the limited data it is presented with.
Typically, AI is trained on human-generated data. In the learning phase it’s picking up on connections between training data and desired outcome, and it’s reinforcing them, or ‘setting them in stone,’ so to speak. This characteristic stresses the importance of understanding and taking into consideration that we, as humans, are biased and our brains are unconsciously making assumptions and taking decision-shortcuts to make our lives easier. But as we all know, with great power comes great responsibility, and workers who are dealing with data should face the need to unbias themselves when collecting and processing data. By doing so, we can avoid the creation of unfair results that causes different subpopulations of people to be overlooked compared to others. Especially people who have been overlooked or discriminated against in the past.
Let’s have a look at one of the most well-known types of biases: the gender bias. When not taking into account how the gender variable could influence a model, you might end up with catastrophic results. For example, in 2018 the news picked up the story about Amazon using an AI recruiting tool that showed bias against women. The root cause was related to the data on which the model was trained on, collecting patterns in resumes submitted to the company over a 10-year period. With the tech industry being dominated mostly by men, Amazon’s model taught itself that male candidates were preferable as the majority of resumes received were including males and not females.
Most of the biases that we see in machine learning today are not intentionally aimed at harming a specific group of people, but they may have different root causes. A general lack of critical thinking or missed perspectives in the elaboration of the datasets or models created can end up negatively affecting human lives in high-risk scenarios.
However, as important as it is to be careful, it is also practically impossible to make all the connections ourselves and foresee every association that the algorithm can make. Therefore it’s extremely important to start by double-checking which features are important to the model you wish to create.
Correct answers to (in)correct questions
Koalas are very peculiar animals and their one-item diet is a unique food regime in the natural world. Being their only food source, nothing makes their mouths water like eucalyptus leaves. However, it’s not only a matter of pleasure, as their survival is entirely dependent on their ability to find and consume them. Seemingly, this does not look like a difficult task as eucalyptus trees are definitely not rare and the poisonous nature of its leaves take out competition, providing koalas access to a relatively untapped food resource. But problems are always right around the corner ...
When a koala is left with nothing else than eucalyptus leaves which have fallen from the tree, the animal fails to recognise them as food, and thus dies from starvation.
Eucalyptus leaves have already a nutritive value close to zero--let alone when they are already on the ground, dried out. Plus, walking on the ground is more dangerous as they become an easier target for predators. So it’s understandable why Koalas would prefer to eat fresh, direct-from-the-tree eucalyptus leaves.
But there is only one explanation why koalas will not eat anything other than eucalyptus leaves fallen from the tree: They are just not very smart, and lack the higher-level cognition and understanding that many other animals have when determining food sources.
What happens to koalas can easily happen to ML models, but hopefully with less dramatic consequences.
Explainable AI comes in handy and it helps to validate if your model is learning what you want it to learn or it is just following the shortest path to extract the best output based on the data it receives.
An already-iconic example of a “shortcut” in machine learning comes from the University of Washington. The deep learning model was built and trained to label images of huskies and wolves--not a simple task considering that huskies and wolves look very similar and even humans struggle to differentiate them. However, the model maintained a very high accuracy of 90% positive identification. How?
It turned out the model didn’t learn how to distinguish huskies from wolves, but instead learned that in the majority of the photos of wolves there was snow, whereas in the photos with dogs there was no snow. In essence, the deep learning model built an elaborate snow detector.
Why did this happen? Because of the data the model was trained and validated on. Most of the pictures of wolves were indeed in the snow, and the majority of dog photos were taken on grass. There were some individual cases where dogs were on snow or wolves were on the grass and in those cases the model made the wrong prediction.That explains the accuracy of only 90%.
The source of this success/failure was uncovered by explaining what the model is paying attention to. It was done by isolating parts of it from the input data. After plotting the results it became clear the decision was based purely on the presence or absence of snow in the pictures. Not quite the impact of racial or gender bias, but a bias nevertheless1.

Predictors like this are called Clever Hans predictors--the name originated from the Clever Hans horse. It was believed the horse knew math and knew how to perform arithmetic tasks. People in the audience were shouting numbers to him and in response, he was tapping his hoof an equal number of times to the result. It looked like he actually knew how to solve them, but in reality the horse was just responding to the body language of his trainer who was unaware of those involuntary cues he was giving to the animal.
There is nothing worse than a very powerful and elaborate model which is solving the wrong task. It’s crucial to look critically at the performance metrics of your model--and the truth is, the better the metrics, the more critical you should be. Focusing on catching all the possible mistakes in the development phase can help save you and your team a lot of time, stress and resources.
Keep your model healthy
Explainable AI is a great tool not only in the pre-deployment phase but also post-deployment. It’s not enough to know how your model behaves and performs during the development phase--it’s also crucial to ensure it behaves and performs well when it’s running on live data.
Machine learning models are probabilistic and their performance can change over time, as the data they were trained on can vary along the way .
Let’s have a look at how changes in our world can affect the validity of machine learning models.
Context is key
Consider Natural Language Processing models trained to judge if a given sentence is positive or negative. Back in 2019, when it was trained, it was performing really well on all 10 languages trained, but a year later its performance decreased significantly for all of them.
Why? In 2019, the sentence “Rob had Corona last week” was a relatively positive sentence about Rob having a Corona beer. In 2020, the meaning changed completely, but the models trained in 2019 were not aware because they were not given any context regarding this change.
With good, detailed monitoring of the running ML models, identifying and fixing mistakes like this can be done much faster. Explainability provides immediate visibility into errors, and can contextualize reasons why they happened in the first place, thus speeding up the fixing process. Looking after one machine learning model is a tedious but manageable job; however, when the project grows from 1 to 10 models it makes it impossible to manage old models while developing new ones. At Media Distillery we are very keen on creating dashboards with metrics updated in real-time, which keeps our services healthy while speeding up the search and fix of bugs.
Therefore, having very good detailed monitoring makes this task a lot easier, more manageable, and efficient.
Examples of monitoring charts at Media Distillery
Explainable AI is shaping the future
Explainability becomes an even more pressing matter in the light of newly proposed EU regulations regarding AI. Margrethe Vestager, Executive Vice President for A Europe Fit for the Digital Age, has said:
“On Artificial Intelligence, trust is a must, not a nice to have. With these landmark rules, the EU is spearheading the development of new global norms to make sure AI can be trusted.”
Some of the biggest companies are already integrating explainability into their product, which will lead to more of their users trusting their solution. For example, Facebook did it some time ago for their low-risk ads engine, allowing users to understand why they are seeing certain ads on their feed.
That is why it’s important to act now. At Media Distillery we are making an effort to make all our AI algorithms more explainable and we will show you how we are achieving this in the next episode.
1 source: https://theblue.ai/blog/lime-models-explanation/
